
")
")
")
")
")





Enterprise teams rarely struggle to build a chat interface now-a-days. They struggle to make it work reliably at scale. A VP of Engineering evaluating chat systems is not asking how to render messages. They are asking how the system behaves when concurrency spikes, when message delivery fails silently, or when latency increases across regions.
Chat systems are deceptively complex. They combine real-time infrastructure, distributed systems, mobile performance constraints, and user expectations shaped by products like WhatsApp and Slack.
The challenge intensifies in React Native environments. Teams must manage real-time data flow over unreliable mobile networks while keeping the app responsive and battery-efficient.This is where most internal builds begin to show stress.
Early implementations rely on REST polling, basic WebSocket setups, or monolithic backends. These approaches work during MVP stages but collapse under enterprise usage patterns.
The result is predictable: delivery inconsistencies, scaling bottlenecks, rising infrastructure costs, and fragmented developer ownership.
Why Chat Systems Break at Scale
Chat workloads behave differently from typical CRUD applications. They are write-heavy, latency-sensitive, and demand strong ordering guarantees.
Three failure patterns consistently appear in large deployments:
- Connection management bottlenecks: WebSocket connections do not scale linearly. Managing millions of concurrent connections requires distributed connection handling and intelligent load balancing.
- Message ordering and delivery gaps: Users expect strict ordering. Distributed systems introduce race conditions, retries, and eventual consistency challenges that can disrupt message flow.
- Backend overload during traffic spikes: Events like product launches or live sessions create sudden surges. Without buffering layers, backend systems become overwhelmed.
According to publicly available engineering discussions from companies like Slack and Discord, real-time messaging systems must handle millions of events per second while maintaining sub-100ms latency expectations. That benchmark becomes a baseline expectation even for enterprise applications.
The takeaway is clear: chat systems must be designed as real-time distributed systems from the beginning, not incrementally patched later.
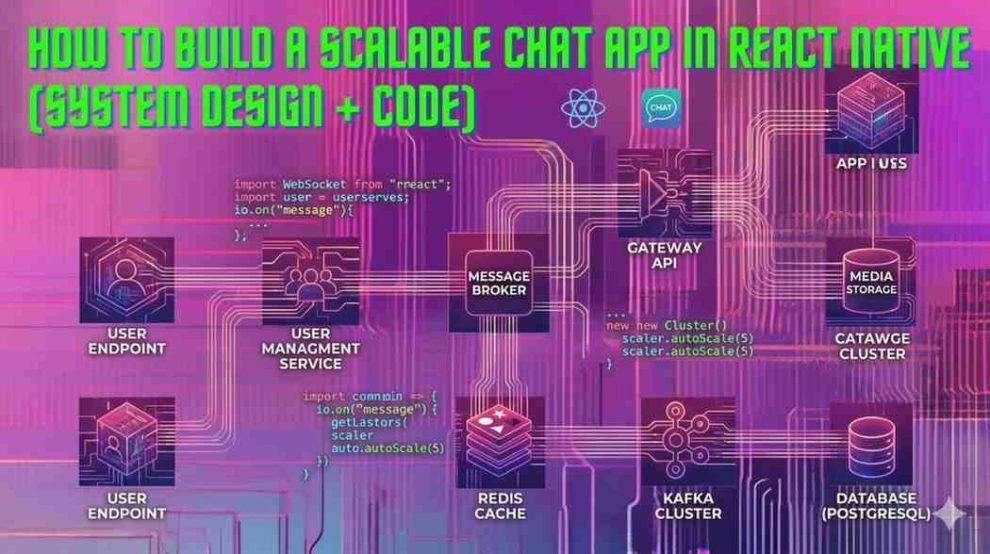
A Reference Architecture That Actually Scales
A scalable chat system is not a single service. It is a coordinated set of specialized components.
At a high level, enterprise-grade chat architectures include:
- Client Layer (React Native): Handles UI, local caching, and connection lifecycle.
- Realtime Gateway (WebSocket Layer): Maintains persistent connections and routes messages.
- Message Queue / Streaming Layer: Buffers events and decouples producers from consumers.
- Message Processing Services: Handle delivery logic, retries, fan-out, and notifications.
- Storage Layer: Stores messages, metadata, and conversation state.
- Push Notification Service: Ensures delivery when users are offline.
This architecture introduces controlled complexity, but it solves the core scaling problem: decoupling.
Instead of a single backend handling everything, responsibilities are distributed across layers that scale independently.
For example, the WebSocket layer can scale horizontally without affecting message persistence. Similarly, message queues absorb spikes without overwhelming downstream services. This separation is what allows systems to handle millions of users without degrading performance.
Implementing Chat in React Native: What Actually Breaks in Production
Most implementations fail not because of UI complexity, but because of state and network behavior under real-world conditions.
At scale, React Native chat systems must handle three realities simultaneously: intermittent connectivity, high message volume, and strict user expectations around delivery and ordering.
The first failure point is connection lifecycle management. Mobile devices frequently move between network states, Wi-Fi, LTE, offline. A naive WebSocket implementation drops messages or duplicates them during reconnection. Mature systems implement session recovery, sequence tracking, and resumable streams rather than treating each connection as stateless.
The second challenge is message consistency. Enterprise teams must decide early between eventual consistency and strong ordering guarantees. Without explicit handling, users will see messages arrive out of order during retries or multi-device sync. Production systems solve this with server-assigned timestamps, client-side ordering buffers, and idempotent message processing.
The third, and often underestimated, challenge is offline-first synchronization. Users expect messages to send even when connectivity is unstable. This requires local persistence, queueing, and replay mechanisms. Instead of pushing every message directly to the server, clients maintain an outbound queue that syncs when connectivity stabilizes.
Performance also becomes a constraint at scale. Conversations with thousands of messages can degrade rendering performance if not handled carefully. Virtualized lists, pagination strategies, and selective hydration of message history are essential to maintain responsiveness.
The difference between a working chat app and a scalable one lies in how these edge cases are handled, not in how messages are displayed.
Operational Reality: Reliability, Cost, and Observability
Building the system is only half the problem. Operating it is where complexity compounds.
Reliability becomes a constant concern. Message delivery must be guaranteed even under failure conditions. This requires retry mechanisms, dead-letter queues, and idempotent processing.
Cost management is another hidden challenge. Persistent connections, real-time processing, and storage growth create non-linear cost curves. Without optimization, infrastructure expenses can escalate quickly.
Observability is often overlooked in early implementations. Yet it is critical for diagnosing issues in distributed chat systems. Effective teams invest in:
- End-to-end tracing for message flows
- Real-time monitoring of connection health
- Alerting systems for delivery failures
Without visibility, debugging chat systems becomes nearly impossible. Failures often occur across multiple services, making root cause analysis difficult.
Build vs Buy: Where Most Enterprise Teams Miscalculate
At enterprise scale, the build vs buy decision is less about capability and more about long-term ownership.
Most teams underestimate chat system complexity by a significant margin. What starts as a 3–4 month initiative often expands into a multi-quarter effort once reliability, scaling, and operational concerns surface.
A more effective way to evaluate this decision is through constraints:
Build is viable when:
- Chat is a core product capability, not a supporting feature
- The organization can dedicate a long-term team to real-time infrastructure
- There is a need for deep customization in delivery logic, compliance, or data control
Buy is typically the better path when:
- Chat is an enabling feature within a larger platform
- Time-to-market is critical
- The organization wants to avoid managing real-time infrastructure at scale
Platforms like Stream and CometChat reduce initial complexity, but introduce tradeoffs around cost predictability and flexibility at scale.
Engineering partners bring a different value. Teams like Geeky Ants are often engaged when organizations choose to build but want to avoid common architectural mistakes, particularly in React Native ecosystems where frontend and backend decisions are tightly coupled. Their role is less about implementation alone and more about ensuring that early system design decisions do not create long-term scaling constraints.
The key is not choosing between build or buy in isolation. It is understanding the cost of being wrong, and designing for the next phase of growth, not just the current release.
A Hard Truth: Most Chat Systems Get Rewritten
Across enterprise teams, a consistent pattern emerges: the first version of a chat system rarely survives scale.
Initial implementations optimize for speed. They rely on simplified architectures, minimal buffering, and limited observability. These systems perform well in controlled environments but begin to fail under production load, typically within 12 to 18 months.
The rewrite is not driven by feature gaps. It is driven by:
- message delivery inconsistencies
- rising infrastructure costs
- inability to debug failures across distributed components
This is where architectural decisions made early become expensive to reverse.
Teams that avoid this cycle treat chat as a platform capability from day one. They invest in separation of concerns, introduce buffering layers early, and prioritize observability before issues arise.
The cost of over-engineering is visible. The cost of under-engineering appears later, often at a much larger scale.
Closing Perspective: Scaling Chat Requires Early Correction, Not Late Fixes
Chat systems do not fail suddenly. They degrade gradually, through missed messages, delayed delivery, and rising operational overhead.
By the time these issues become visible to users, the underlying architectural constraints are already difficult to change.
For engineering leaders, the more effective approach is not reacting to scale problems, but identifying them early, before they are embedded into the system.
This is where a structured evaluation becomes valuable. Not a full rebuild. Not a vendor switch. Just a focused review of how the current architecture will behave under increased load, concurrency, and geographic distribution.
In many cases, small adjustments, introducing a queue, restructuring message flow, improving connection handling, can prevent larger failures later.
The challenge is knowing where those adjustments matter.
And that perspective typically comes from teams that have seen how chat systems evolve beyond the initial build phase.








")
")
")
")
")
Add Comment